| Home • Forum • RSS • PGP • Alerts • Links • (D) |
|
|
|
|
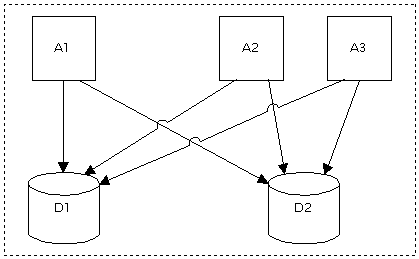
Integration of databases Comment on this articleNote: this text was adapted from a presentation I held at a Belgian company in 2000. 1. The problemThe problem described and attacked in this document:
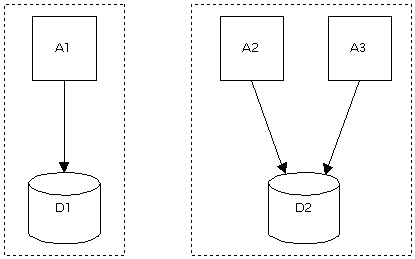
Figure 1: 3 apps, 2 databases, 2 teams, 1 or more problems 2. Desired outcomes
3. Possible solutions
3.1. Database synchronisationThere are a number of commercial techniques to synchronise databases. The stuff included with the database software generally won’t do anything useful except synchronise updates in one direction (master to slave) and even then generally only between identical database structures. So forget about them already. Commercial packages are very… commercial . I.e. expensive. Not only that, but I actually have no idea what they do. So forget about those too, for now.
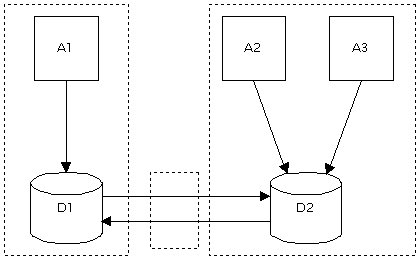
Figure 2: 2 teams plus a trigger writing/maintenance team So, it’s down to do-it-yourself. There are ways of synchronising using asynch methods, including messaging. That’s great for on-the-road salesmen and scheduling. But it’s not so great for what we need here. The obvious technique to use is a combination of triggers and stored procedures. It also turnes out that this is the simplest of the techniques to implement, and also the most efficient. Examples and descriptions below. 3.2. Common data access layersOh, yes, definitely. This technique isolates the dependencies on the exact data storage structure to a single layer. It eliminates code duplications (well, “reduces” is perhaps more accurate) and allows team decoupling. On the other hand, in itself it only moves the dependency on the data structure to a dependency on the structure of the data layer. It does allow the data structure (the database proper) to change without changing the data layer interface to the processes. But if all processes dogmatically have to use one and the same data access layer, there’s no point in ever changing anything in the database itself (since there’s no change in the layer the processes actually use). In other words, if an evolving application needs extra services or data from the database, the data layer itself needs changing. But then, if we don’t take care, we’re back in exactly the same spot we were when we didn’t have a data access layer and had to change the database structure itself.
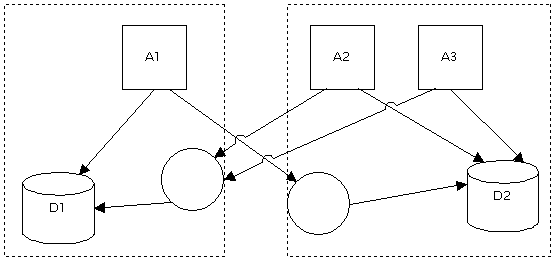
Figure 3: Implementing DAL objects for other applications only, while using proprietary access to database for "old" app. So, what I’m trying to say here is that just interposing a data access layer and then ordering everyone to use it (or else…), is futile. You’re only moving the problem around. What a data access layer can do, and must do, is make several different styles of access and data available to the different clients (processes) in such a way that if one of the clients need new or modified services, the others don’t need to see anything change. This is not trivial at all to design and implement, or trivial to manage team-wise. But it is at least possible, which is a great step forwards.
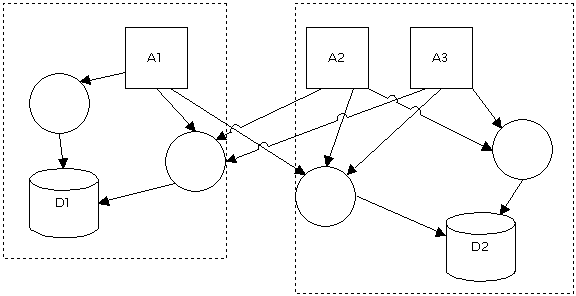
Figure 4: Using DAL components for all applications, after re-engineering "old" apps. By now, you’re probably having visions of C++ COM objects under MTS or COM+ as a loadbalanced, pooled and super sexy data access layer. It could be. I’d like it to be. But it could just as well be stored procedures and views, the way Codd saw it in the 1960’s. No real difference there. The Codd way would probably be as performant (or better, I’m sad to say). But it’s so five years ago. 3.3. Common data access and process layersGoing one step further, large parts of the client applications can be delegated to independent sub-teams. For instance, the patient selection screen can be an ActiveX control, tied into it’s own process layer COM object, which uses a shared patient administrative data access layer component. So if anything needs changing in the patient admin data or the view of them, the patient admin team updates whatever they feel like updating and all client apps get the latest look-and-feel. Or, of course, a client app can have it’s own listview and look and just use the second tier, the process layer, of the patient admin group. It would still get to use the current and new functionality of the patient admin group, but would control the look-and-feel within their own client code. The whole discussion of business and interface layering is very interesting, and even though I’m itching to ramble on about it, it doesn’t belong in this document. So I’ll, reluctantly, desist. You narrowly escaped. 3.4. Integration of applications and teamsMerging the application development teams into one large team enables you to manage the data schemas centrally and to accommodate all needs by evolving the one and only database according to everybody’s need. Sounds great? So did communism and centralized planning, and look what happened to Russia.
Figure 5: Russia In fact, practically every part of modern development technique is aimed at decoupling development into small, independent efforts and teams. The very idea of merging development is so anathema to good practices that it’s not worth wasting breath on. You wanna go the way of the Russian empire, by all means, merge the teams. Get over it already. 4. Triggers4.1. ExamplesI have real world examples of trigger code to synch databases, if anybody wants to see it. There’s no point in including it here, but if you ask nicely, I'll dig it up for you. 4.2. Technical implications and examplesThe two “big names”, Oracle and MS SQL, have all the needed provisions. Sybase, I don’t know, but I guess it’s similar to MS SQL 6.5, with all the warts, since MS SQL 6.5 is derived from it. Independently important note: triggers can couple more than two databases, but I’m using only two in examples and discussions. 4.2.1. What we needWe need “before” or “after” triggers, slightly different requirements. We need stored procedures allowing access to other database instances within transactions. We may need transactional access to physically distant databases of same or other brand. 4.2.2. MS SQL 6.5This one I know and love/hate. Has only “after” triggers. That means that any codes you plug into tables and expect the triggers to remove and/or change before committing, really has to satisfy foreign key constraints. So if you use “magic codes” to communicate to or between triggers, those codes must physically exist in the constraining base tables. You have to document this real well to protect yourself from overzealous database managers in the future. 6.5 has a limit on how many tables, foreign keys and indexes can be involved in one transaction. If a trigger goes across databases within a transaction (using stored procedures), the total in the transaction is the total of both databases and can exceed the allowed limit. This stuff is really, really poorly documented and feels like hitting a brick wall. The solution is to reduce indexes and FK’s until it works. The problem only really occurs in poorly designed databases where the developers have heaped indexes on humongous tables in usually misconceived attempts at improving abominable performance. So be it, you’re stuck with it. So far, I was always able to get below this limit and get things to run, simply by dropping indexes nobody needed anyway. 4.2.3. MS SQL 7Still has only “after” triggers. But that’s ok. Haven’t worked with it. I do know, however, that the feared transaction limit on tables, FKs and indexes in 6.5 has been doubled. That’s great, but not enough. You may still run into that brick wall. Also has “multiple triggers”, making maintenance somewhat easier. 4.2.4. Oracle 7Has “before” and “after” triggers. Advantage: eliminates having to use “dummy” foreign key values for magic messages between triggers. That’s a relief. Probably has less limitations on number of elements in transactions, but that’s just a guess on my part. Ok, guys, that’s about all I know about Oracle, so shoot me. 4.2.5. Limitations4.2.5.1. Recursion, nestlevels and the fearful HoleTo avoid recursion in the triggers, I used the @NESTLEVEL system variable. This one tells you if the trigger (or stored procedure) was called by other triggers or procedures, and if so to what depth. Only performing replication when this value is equal to one stops the triggers from bouncing. On the other hand, changing tables from a stored procedure disables the replication since @NESTLEVEL is then 2 or higher. This means that any stored procedures must see to the replication themselves. (Implementation by having replication in a stored procedure called from the triggers, so this procedure can also be called from elsewhere.) This hole I don’t know how to plug in MS SQL 6.5. It may be possible in Oracle, though, if there’s a way to pass messages to triggers through system or session variables. 4.2.5.2. Remote databasesTriggering between physically separate databases (running on separate servers) has to be done through transaction monitors. MS claims MTS with DTC can do this even between Oracle and MS SQL. If it can do this Oracle-to-Oracle, I don’t know. Or if Oracle can do this without a transaction monitor by itself. Nothing stops you from implementing part of the synchronisation over message queues, if you’re sure the domain can stand it. It should probably be considered if there’s a pure master/slave relationship and if the slave is unreliable or under somebody else’s control (same thing). 4.2.5.3. Bad trigger codeA certain ERD design and script tool (EW 3.0? I forgot…) had (has?) the habit of writing FK constraints into triggers using a form of “IF UPDATE(…) THEN…” that’s simply wrong. If this kind of code is present in one database, the whole thing goes south if the apps in the other database re-write unchanged column values (as did ODBC and MS Abcess a while back). This kind of shitty trigger code has to be cleaned up manually. Please note that this problem has nothing directly to do with synching two databases, really, only with EW generated trigger code being incompatible with a way of updating data that was used a while back (and may still be in use). But installing synch triggers sometimes gets this bug into the open where you have to stomp on it. 4.3. VersioningEach version of the trigger system is bound to the version of both databases, of course. But not at all to the versions of the client apps. Actually, the maintainer of the triggers needs to have no clue at all about what the databases are used for or by whom. There’s an issue about merging the trigger code with whatever other trigger code is used by the database designers. In MS SQL 6.5, the trigger code had to be cut-and-pasted together. In MS SQL 7 there’s multiple triggers, just as in Oracle, so they can simply be added on. Even though the multiple trigger feature allows more or less mechanical addition of the synch code, it’s still necessary to thouroughly eye-ball the trigger code belonging to each database. Especially if automated ERD design and script tools are used (see “Bad trigger code” above). It’s just a few thousand lines to check anyway, so it’s a piece of cake. Use those eyeballs. 4.4. Third partySooner or later, somebody else will write code accessing your database. No way around it. From that moment on, you have the choice of one of three things:
4.5. Team and managementThe trigger maintenance team needs to know some SQL, obviously. They should also always be consulted on any changes to database structures to make sure there’s a reasonable way to implement the synch triggers. It’s very rarely a major problem to implement them, though. If the used database has a problem with the number of tables, indexes and FKs, the databases may need to be optimised, so the trigger team should have a say in the database structure for this reason too. 5. Data access layersA data access layer (DAL) is a code layer between your database and your client apps. (The client apps may then, if you’re fashionable enough, be divided into user interface and business layers. If so, it’s the business layer that talks to the data access layer.) The DAL consists of collections of functions that the business layer (or client app) can call to get and put data. At first implementation, it usually totally mirrors the structure of the database tables, but from that moment on, you’re free to change the database structure and maintain the DAL function view unchanged. Obviously, the DAL view for “third parties” is what needs to remain unchanged. Your own view needs to change, else what’s the point of changing the database structure? This implies that for each database structure, there are multiple DAL views on it. 5.1. Technical implicationsA DAL can be implemented in a “real” language such as C++ or in Visual Basic. For instance. Or as database views for read access and stored procedures for writes. Or a combination of the two or three. The point is not how it’s implemented, but by whom. (See below). 5.2. VersioningVersioning of any component layer means adding functionality without ever changing or deleting existing functionality, unless it’s guaranteed to be out of use by everybody. The actual implementation of old functionality may have to be changed to follow changes in the database structure, but the client should not be able to see the difference. In case of views, add views. In case of stored procedures, add procedures. In case of COM objects, add interfaces. Of all the implementations, the COM interface identity system is definitely the most manageable. It can be corrupted with a bit of effort to be just as pesky as the other ones, though. 5.3. Third partyJust leave the data access objects those third parties use intact. If their implementation needs to update, cover it under maintenance or charge it. If the third party accesses the database directly, you didn’t keep the passwords very secret, did you? Now you get to choose between splitting database structures and installing triggers (charge the customer) or wasting your breath complaining and moaning about it. And not getting paid; more moaning forthcoming. To avoid the pain, you really, really, should make third parties use your data access objects. That means spreading the word, writing good docs and supporting them (what a concept) as the database changes. It may also mean, horrid thought…, releasing the source code for the data access objects to competitors. If you can’t keep that up, your competitors or customers will access the database behind your back. Then only triggers will help you. 5.4. Team and managementThe responsibility for the DAL and it’s underlying database structure belongs in one coherent team. It’s best to divide the database into congruent “entities”, such as “patients”, “lab results”, “billing” or whatever, and let a person or team be responsible for each entity. Usually, an entity will encompass 5-20 tables and 2-3 alternative DAL function sets. Having the entities managed by separate development teams also encourages de-coupling of dependencies between them. That’s good, by the way. 6. Real world project stages6.1. Get’em running PDQYou get the order. The money’s on the table. Get that stuff running Pretty Damn Quick so you’ll get paid. You know the score. This is the way:
6.2. Maintain the PDQ
6.3. Back to your sensesYou soon realize that even though this stuff works great, you don’t want to tell your children about it (“but dad, it’s not java??!”). So, once it’s running, you can let the teams start interposing data access layer components if and when they’re useful. It’s very important to decide exactly which team is responsible for each component, and which teams will use them. Only when a component is certifiably used by absolutely everyone and bypassed by noone, can you remove the trigger synchs and rely on the components to keep databases consistent. Please take care to protect access to the database with security in such a way that nobody can work directly with the tables. Nobody except the components, of course. Else you’ll sooner or later (let’s just say “yesterday”) find patients in one database that are not to be found in the other. It takes just one developer or doctor let loose with a commandline interface, and one single SQL Insert statement to do the terrible deed. (Then try to explain to an irate anesthesiologist why patient X can be in intensive care, but can’t be moved to the operating room because of duplicate keys…) There’s (almost) no such hole in the trigger synch system, so don’t discard it prematurely. 6.4. Do it better next time and securityThree-tier. Four-tier. Whatever-tier. The more tiers the merrier. (No irony, I really mean it.) The tier security is paramount and should be role-based. That’s the way COM+ is going, by the way. That means, for instance, that access to the patient database tables is allowed for a certain group of COM objects, independent of the logged in user. I.e., it’s up to your datalayer component to decide if it wants to execute a request originating from a certain user. Since the request may already have passed through several tiers, there’s a provision for each component to ask the system for the credentials of all preceding callers/clients, be they components or ultimately logged in users or services. To make all this work right, there has to be a total barrier across layers, so nobody, not even the whiliest hacker/developer can take shortcuts around your components. Else it’s deja-vu all over again. Briefly: security isn’t just a disgusting extra user requirement anymore, it has become an essential part of the layering of your applications. It’s actually the only way of ensuring “ownership” and encapsulation of design decisions and independency of development teams. |
| TOP |